In this work, we consider a novel setting where the global task distribution can be partitioned into a union of conditional task distributions. We then examine the use of task-specific prompts and prediction heads for learning the prior information associated with the conditional task distribution using a one-layer attention model. Our results on loss landscape show that task-specific prompts facilitate a covariance-mean decoupling where prompt-tuning explains the conditional mean of the distribution whereas the variance is learned/explained through in-context learning. Incorporating task-specific head further aids this process by entirely decoupling estimation of mean and variance components. This covariance-mean perspective similarly explains how jointly training prompt and attention weights can provably help over fine-tuning after pretraining.
2024
NeurIPS
Fine-grained Analysis of In-context Linear Estimation: Data, Architecture, and Beyond
Yingcong Li, Ankit Singh Rawat, and Samet Oymak
Advances in Neural Information Processing Systems, 2024
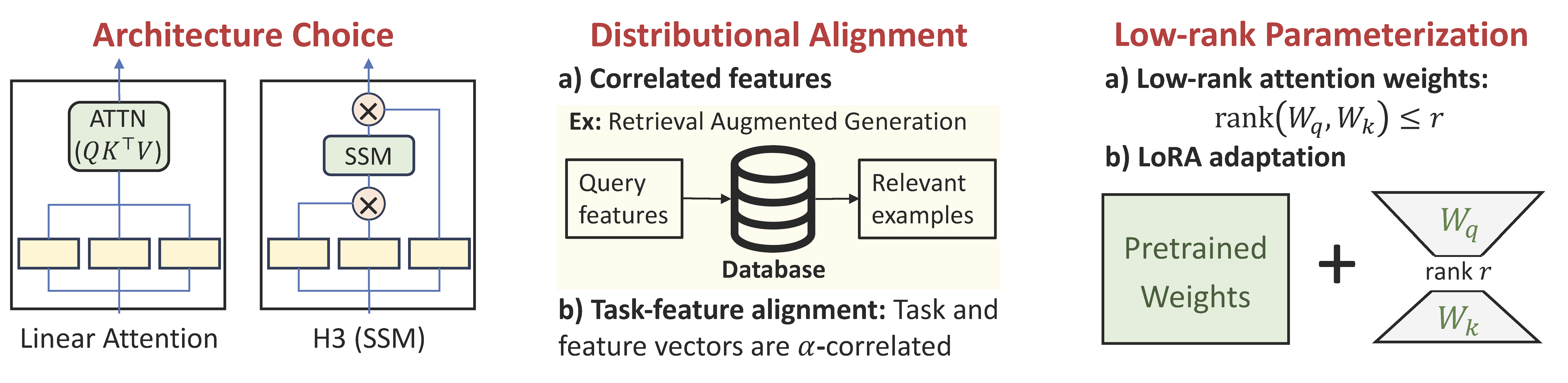
In this work, we develop a stronger characterization of the optimization landscape of ICL through contributions on architectures, low-rank parameterization, and correlated designs: (1) We study the landscape of 1-layer linear attention/H3 models and prove that both implement 1-step preconditioned gradient descent (PGD). Additionally, thanks to its native convolution filters, H3 also has the advantage of implementing sample weighting and outperforming linear attention. (2) We provide new risk bounds for RAG and task-feature alignment which reveal how ICL sample complexity benefits from distributional alignment. (3) We derive the optimal risk for low-rank parameterized attention weights in terms of covariance spectrum. Through this, we also shed light on how LoRA can adapt to a new distribution by capturing the shift between task covariances.
ICML
From Self-Attention to Markov Models: Unveiling the Dynamics of Generative Transformers
M Emrullah Ildiz, Yixiao Huang, Yingcong Li, and 2 more authors
International Conference on Machine Learning, 2024
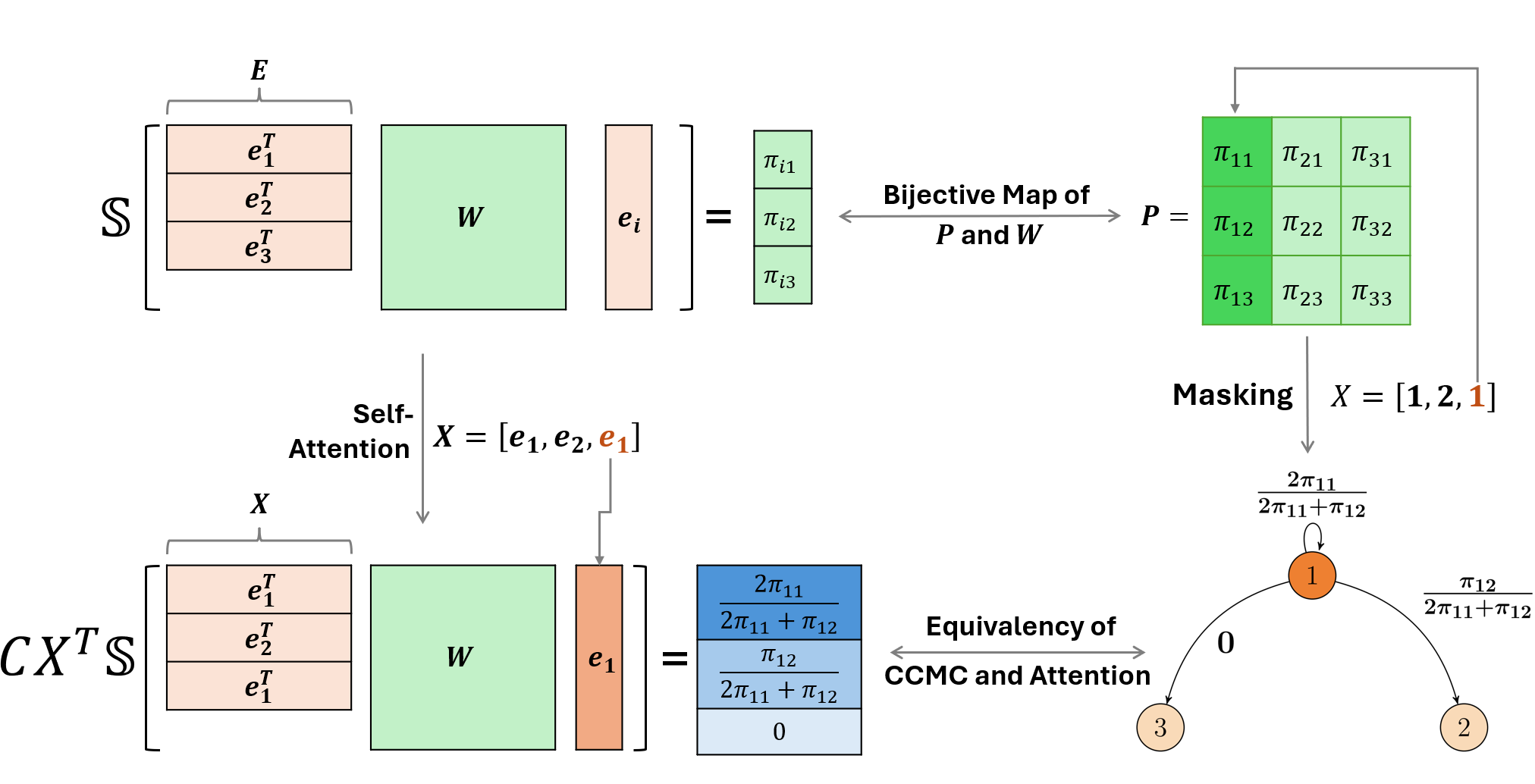
In this work, we study learning a 1-layer self-attention model from a set of prompts and associated output data sampled from the model. We first establish a precise mapping between the self-attention mechanism and Markov models. Building on this formalism, we develop identifiability/coverage conditions for the prompt distribution and establish sample complexity guarantees under IID samples. Finally, we study the problem of learning from a single output trajectory generated from an initial prompt. This provides a mathematical explanation to the tendency of modern LLMs to generate repetitive text.
ICML workshop
Can Mamba In-Context Learn Task Mixtures?
Yingcong Li, Xupeng Wei, Haonan Zhao, and 1 more author
In ICML 2024 Workshop on In-Context Learning, 2024
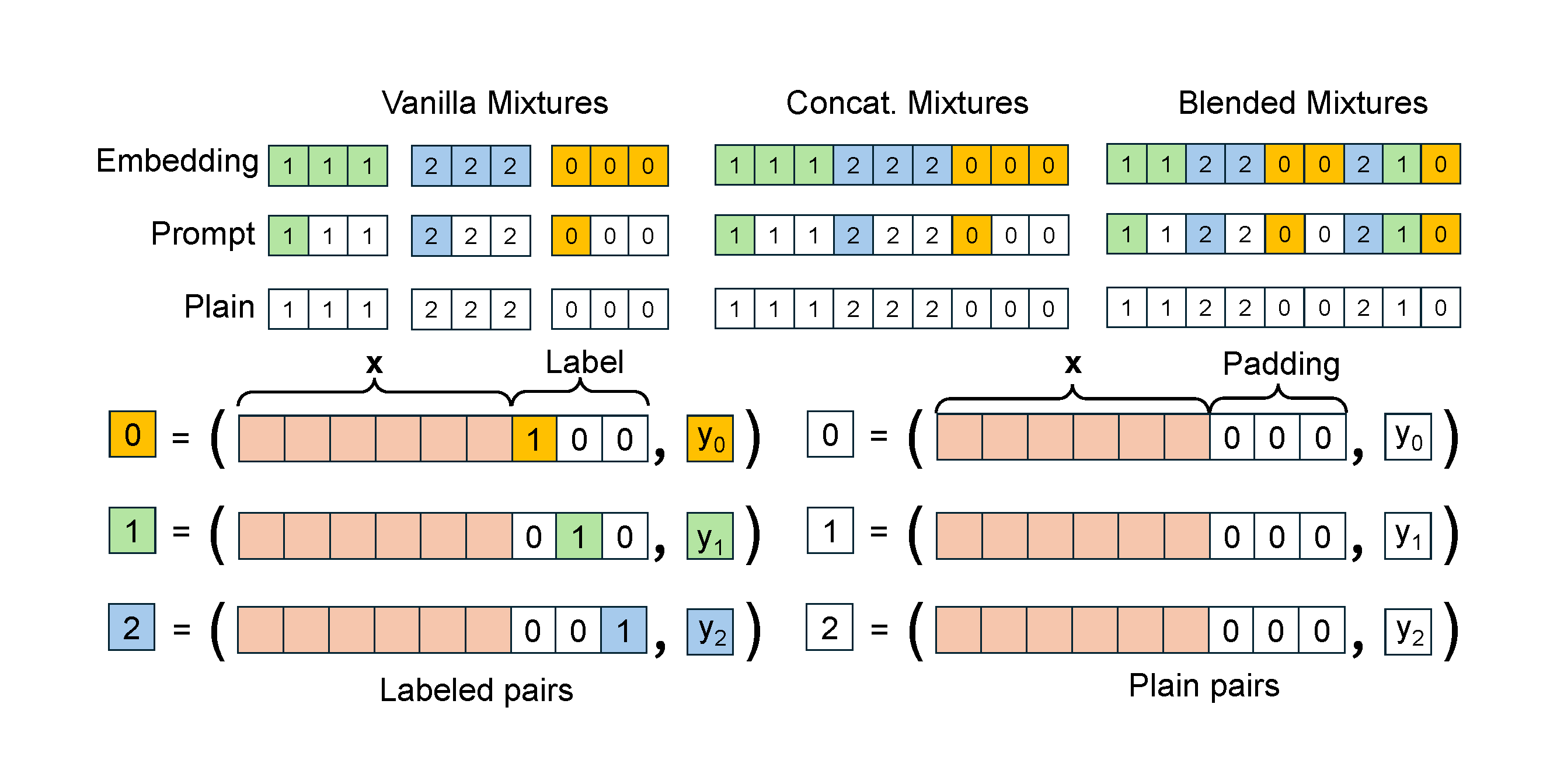
In this work, we explore the Mamba performance in mixed ICL tasks, in a degree from low to high, and from labeled to unlabeled. We show that Mamba is capable of learning ICL mixtures, reaching the performance of single ICL task and Transformer baselines. Moreover, Mamba converges faster and shows more stable performances than Transformers, allowing Mamba to handle longer context lengths and more complicated prompt structures. Different learning dynamics in different ICL tasks are also observed.
AISTATS
Mechanics of next token prediction with self-attention
Yingcong Li*, Yixiao Huang*, Muhammed E Ildiz, and 2 more authors
In International Conference on Artificial Intelligence and Statistics, 2024
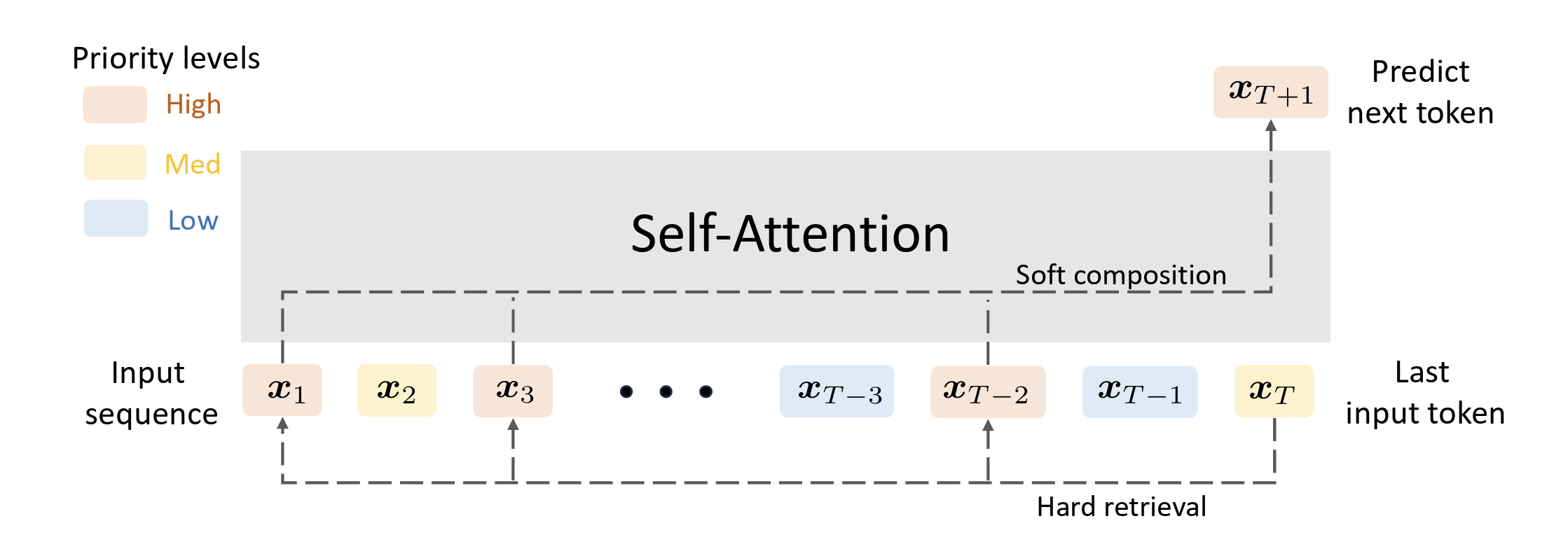
In this work, we ask: What does a single self-attention layer learn from next-token prediction? We show that training self-attention with GD learns an automaton which generates the next token in two distinct steps: (1) Hard retrieval: Given input sequence, self-attention precisely selects the high-priority input tokens associated with the last input token. (2) Soft composition: It then creates a convex combination of the high-priority tokens from which the next token can be sampled. Our theory relies on decomposing the model weights into a directional component and a finite component that correspond to hard retrieval and soft composition steps respectively.
NeurIPS
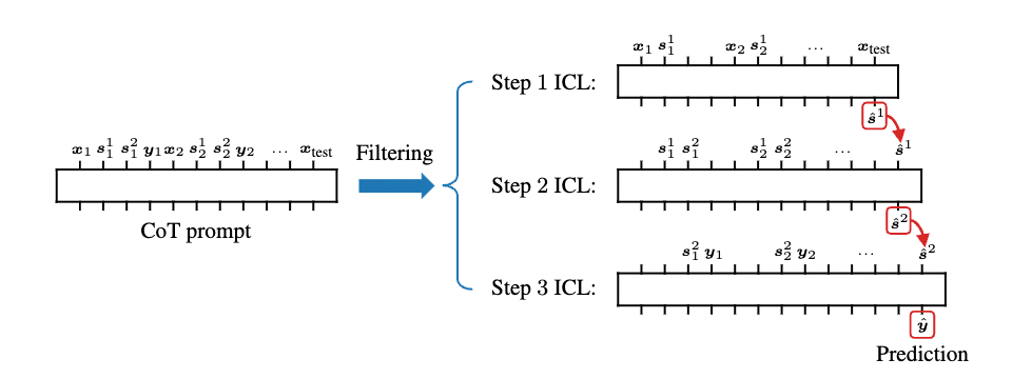
Dissecting chain-of-thought: Compositionality through in-context filtering and learning
Yingcong Li, Kartik Sreenivasan, Angeliki Giannou, and 2 more authors
Advances in Neural Information Processing Systems, 2024
Our study finds that the success of CoT can be attributed to breaking down in-context learning of a compositional function into two distinct phases: focusing on and filtering data related to each step of the composition and in-context learning the single-step composition function. Through both experimental and theoretical evidence, we demonstrate how CoT significantly reduces the sample complexity of ICL and facilitates the learning of complex functions that non-CoT methods struggle with.
2023
in submission
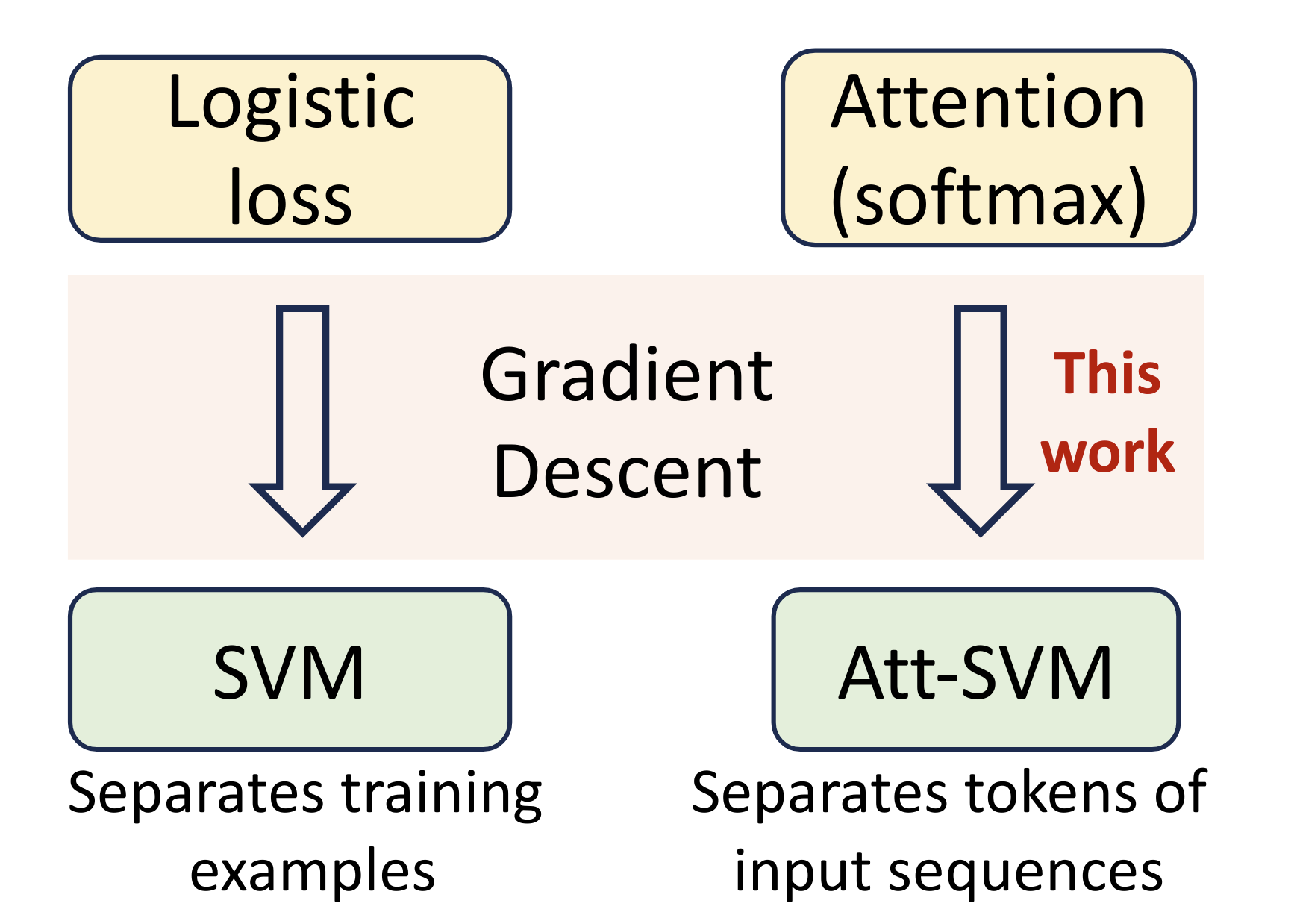
Transformers as support vector machines
Davoud Ataee Tarzanagh*, Yingcong Li*, Christos Thrampoulidis, and 1 more author
In this work, we establish a formal equivalence between the optimization geometry of self-attention and a hard-margin SVM problem that separates optimal input tokens from non-optimal tokens using linear constraints on the outer-products of token pairs. Our findings are applicable to arbitrary datasets and their validity is verified via experiments.
NeurIPS spotlight
Max-margin token selection in attention mechanism
Davoud Ataee Tarzanagh, Yingcong Li, Xuechen Zhang, and 1 more author
Advances in Neural Information Processing Systems, 2023
In this work, we explore the seminal softmax-attention model and prove that running gradient descent converges in direction to a max-margin solution that separates locally-optimal tokens from non-optimal ones. This clearly formalizes attention as an optimal token selection mechanism.
ICML
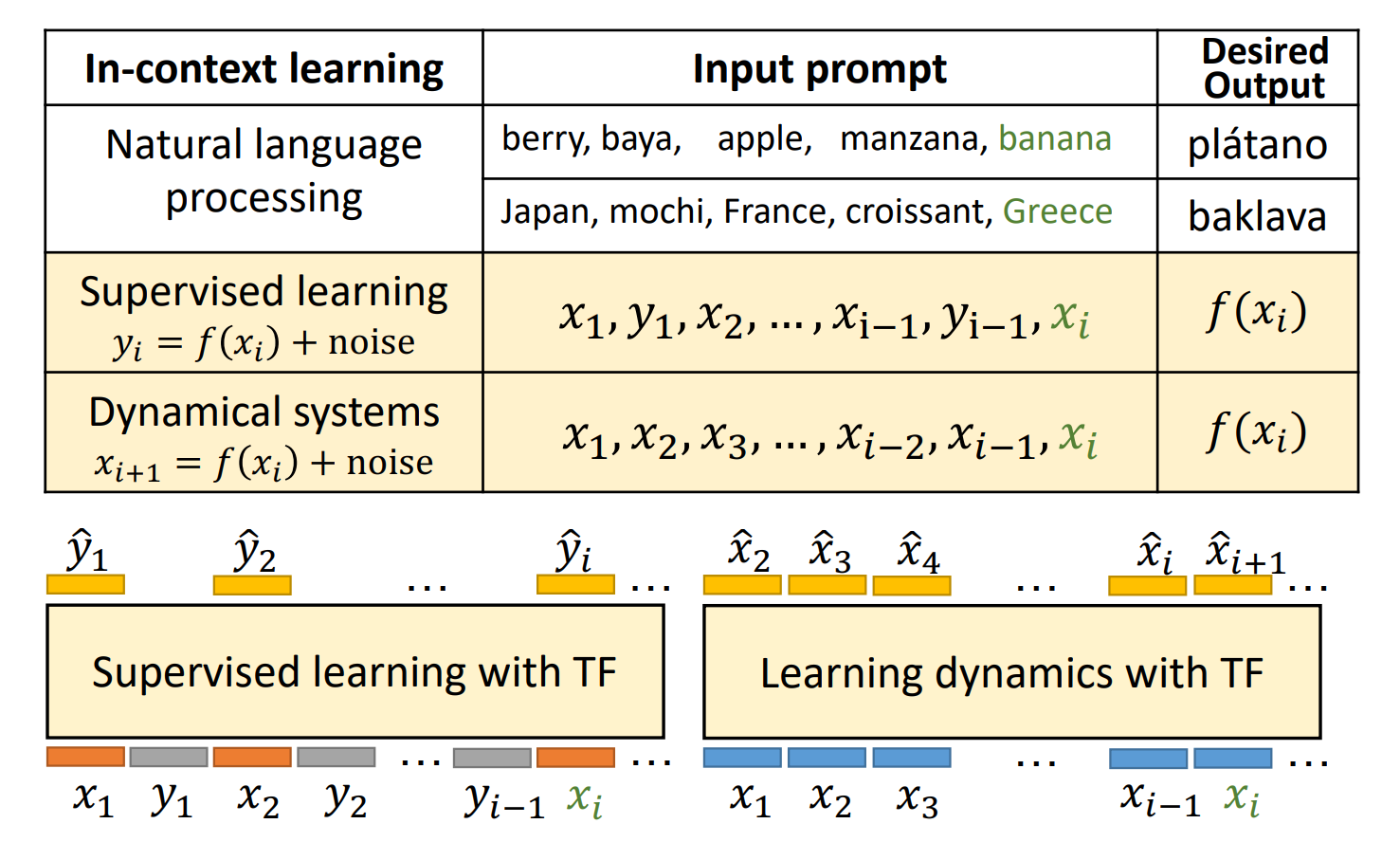
Transformers as algorithms: Generalization and stability in in-context learning
Yingcong Li, Muhammed Emrullah Ildiz, Dimitris Papailiopoulos, and 1 more author
In International Conference on Machine Learning, 2023
In this work, we formalize ICL as an algorithm learning problem where a transformer model implicitly constructs a hypothesis function at inference-time. We first obtain generalization bounds for ICL when the input prompt is (1) a sequence of i.i.d. or (2) a trajectory arising from a dynamical system. We characterize when transformer/attention architecture provably obeys the stability condition and also provide empirical verification. For generalization on unseen tasks, we identify an inductive bias phenomenon in which the transfer learning risk is governed by the task complexity and the number of MTL tasks in a highly predictable manner.
ICASSP
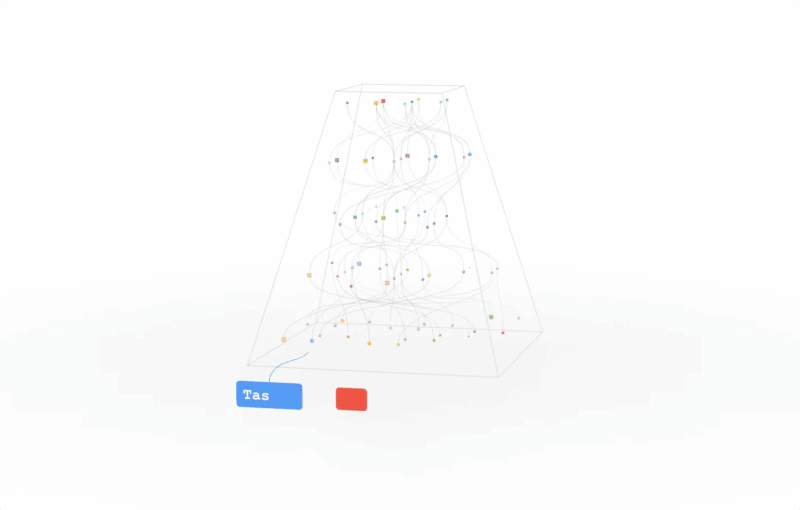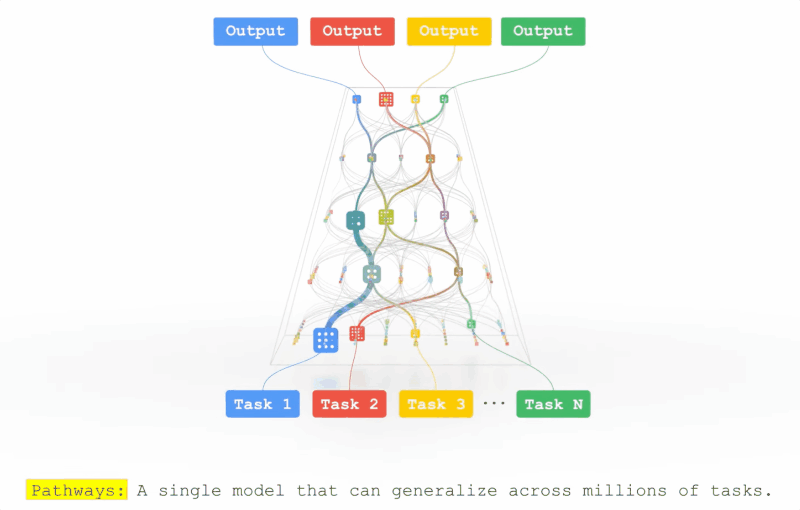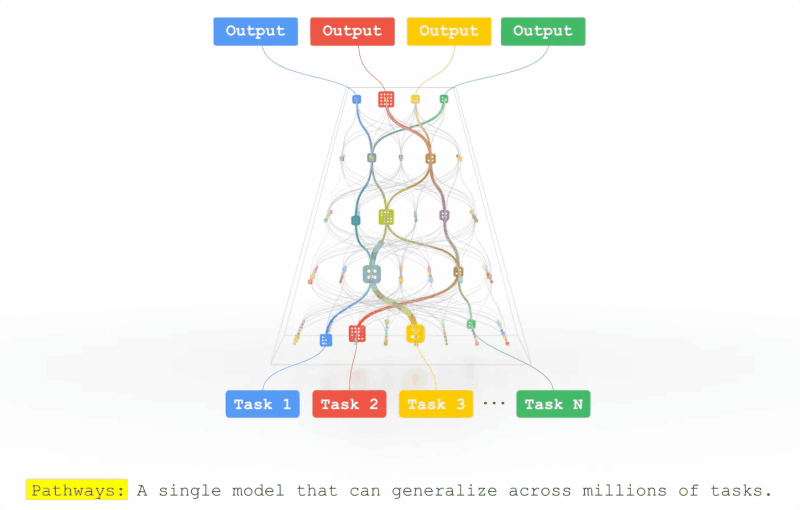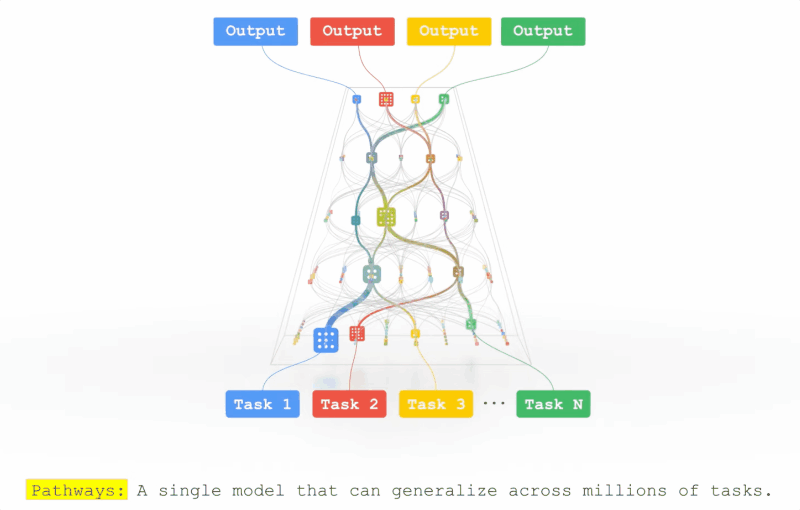
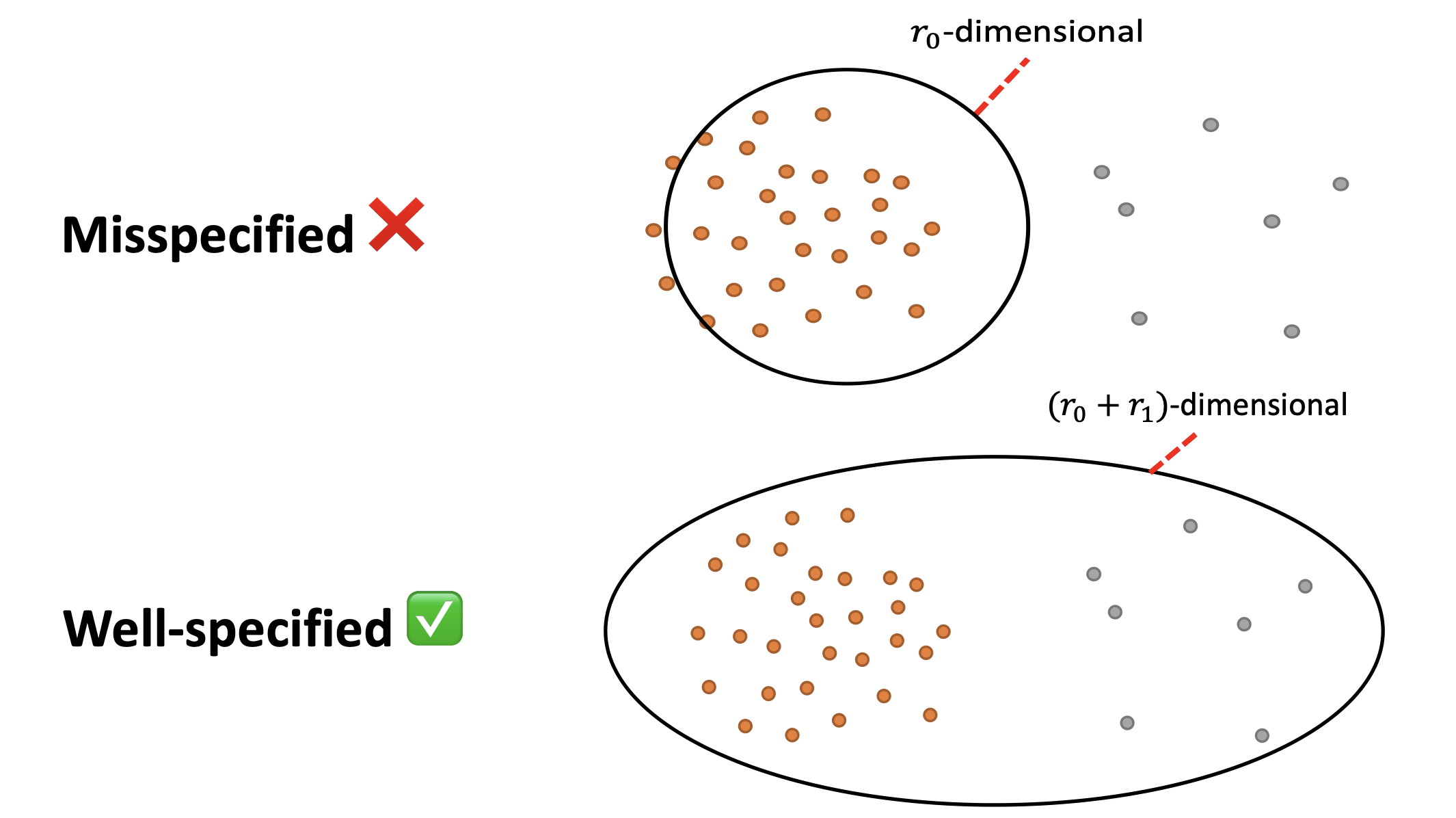
On the fairness of multitask representation learning
Yingcong Li, and Samet Oymak
In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
This work explores the pathways proposal from the lens of statistical learning: We first develop novel generalization bounds for ERM problems learning multiple tasks over multiple paths. In conjunction, we formalize the benefits of resulting multipath representation when adapting to new downstream tasks. Our bounds are expressed in terms of Gaussian complexity, lead to tangible guarantees for the class of linear representations, and provide novel insights into the quality and benefits of a multipath representation.
AAAI
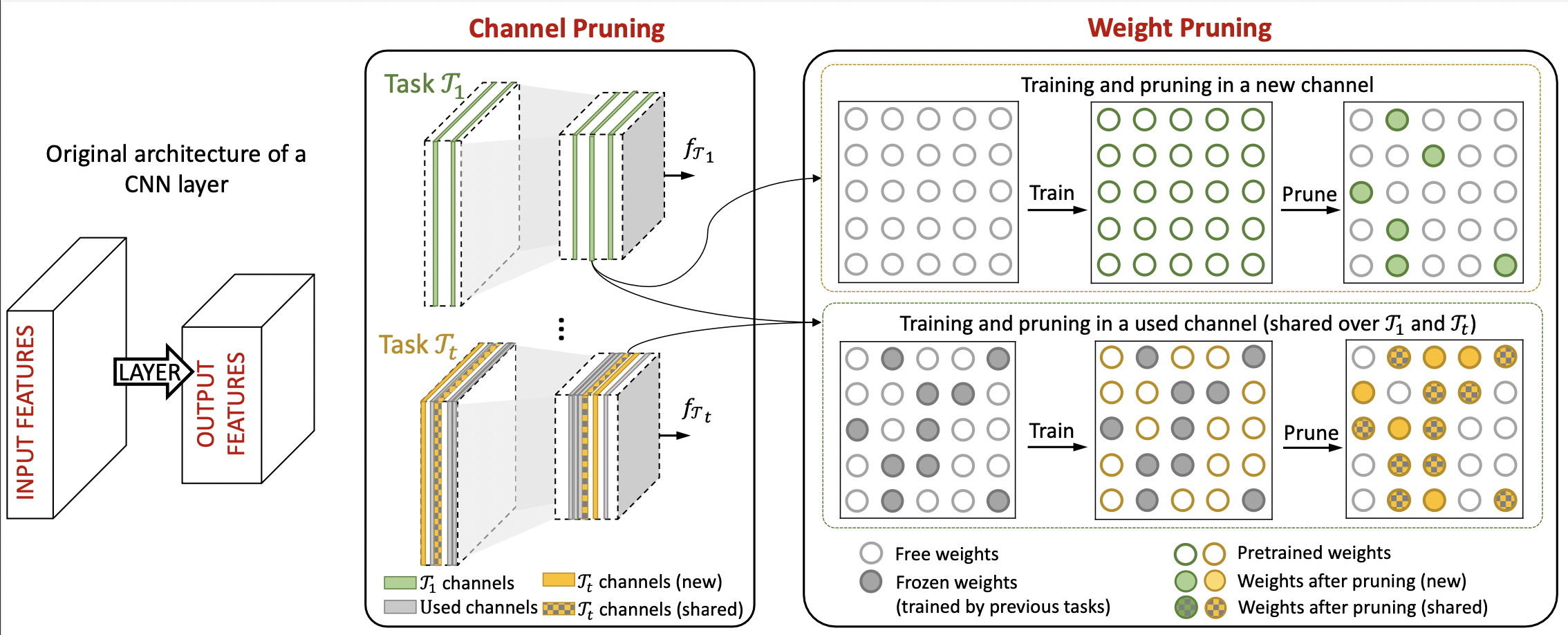
Stochastic contextual bandits with long horizon rewards
Yuzhen Qin, Yingcong Li, Fabio Pasqualetti, and 2 more authors
In Proceedings of the AAAI Conference on Artificial Intelligence, 2023
In this work, we study the problem of continual learning (CL) and focus on zero-forgetting methods. We first provide experiments demonstrating CL can significantly boost sample efficiency when learning new tasks and establish theoretical guarantees by providing sample complexity and generalization error bounds for new tasks. Our analysis and experiments also highlight the importance of the task order. Specifically, we show that CL benefits if the initial tasks have large sample size and high "representation diversity". Finally, we propose an inference-efficient variation of PackNet called Efficient Sparse PackNet (ESPN) which employs joint channel & weight pruning. ESPN embeds tasks in channel-sparse subnets requiring up to 80% less FLOPs to compute while approximately retaining accuracy and is very competitive with a variety of baselines.
2021
AAAI
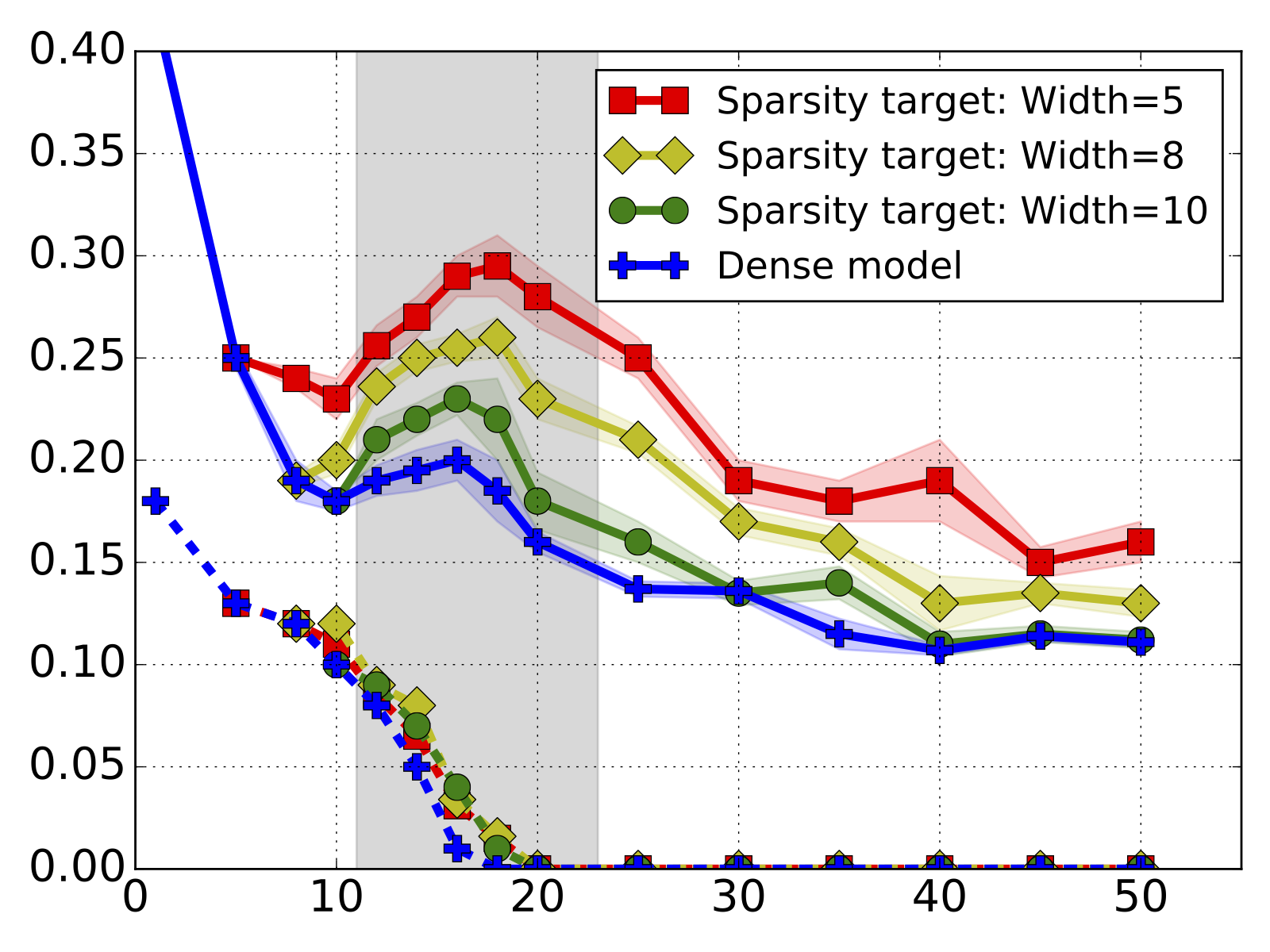
Provable benefits of overparameterization in model compression: From double descent to pruning neural networks
Xiangyu Chang*, Yingcong Li*, Samet Oymak, and 1 more author
In Proceedings of the AAAI Conference on Artificial Intelligence, 2021
Recent empirical evidence indicates that the practice of overparameterization not only benefits training large models, but also assists building lightweight models. This paper sheds light on these empirical findings by theoretically characterizing the high-dimensional asymptotics of model pruning in the overparameterized regime. We analytically identify regimes in which, even if the location of the most informative features is known, we are better off fitting a large model and then pruning rather than simply training with the known informative features. This leads to a new double descent in the training of sparse models: growing the original model, while preserving the target sparsity, improves the test accuracy as one moves beyond the overparameterization threshold. Our analysis further reveals the benefit of retraining by relating it to feature correlations.
 On the fairness of multitask representation learningIn ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
On the fairness of multitask representation learningIn ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023 Stochastic contextual bandits with long horizon rewardsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2023
Stochastic contextual bandits with long horizon rewardsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2023